Are Vision Language Models learning effectively?
Take a look how VLMs learn and the effectiveness of their learning process.
This post contains many subjective opinions based on my personal research and understandings, so please take it with a grain of salt.
Why am I writing this?
DeepSeek R1 was released recently and it’s truly impressive. However, I’ve noticed that R1 doesn’t support vision tasks directly; it seems to manage them, if at all, only through some basic OCR functionality in the background.
Similarly, OpenAI’s O1 hasn’t supported vision tasks yet either. So, why is that?
Perhaps they aren’t ready to invest the time and money into developing a reasoning-based Vision-Language Model (VLM) just yet. This leads to a simple question: “Is it because modern models handle and learn from text data more effortlessly than from vision data?”
Basic concepts we need to know
Before go to my thoughts, let’s take a look at some basic concepts about VLMs.
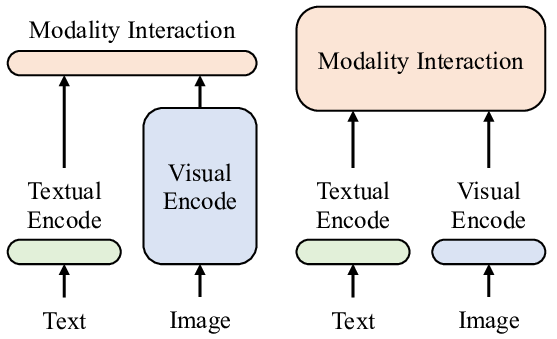
Vision Language Models (VLMs) architecture
VLMs generally consist of:
- Vision Encoder: Processes image data to extract visual features.
- Text Encoder: Transforms textual data into embeddings.
- Multimodal Connector: Aligns and integrates visual and textual features, often through methods like cross-attention or projection layers.
Vision Encoder Architecture
Almost all modern VLMs are leveraging Vision Transformers (ViTs) as their primary image encoder architecture.
Let’s take a look at the ViT:
- Treating images like sequences of words
- ViT uses a standard Transformer encoder
- ViT is trained on a large labeled image data (supervised learning)
My initial thoughts
The Lack of Self-Supervised Learning in ViTs
As you can see, modern VLMs are leveraging Vision Transformers (ViTs) as their primary image encoder architecture.
However, compared to text encoders, originnal ViTs used supervised learning!
The pretraining phases of modern and foundational transformer-based models are all based on self-supervised learning.
From my perspective, self-supervised learning helps models learn more general features from the data. No hacking for the output, much more data to train, no bias or errors from the labels! (more details in the next section)
ViT is lacking in this aspect.
The difference between scalability in Text Encoder and Image Encoder
Text Encoders’ scalability advantage:
- Abundant Unlabeled Text Data: The internet is awash with text data – websites, books, articles, code, social media posts, etc. This data is essentially free and constantly growing.
- Self-Supervised Learning Paradigm: Methods like Masked Language Modeling (MLM) and Next Sentence Prediction (NSP) (in older models like BERT) or just next-token prediction (in GPT-style models) allow models to learn directly from unlabeled text. They create their own “labels” implicitly within the data itself. This means you can train on massive datasets without the expensive and time-consuming process of manual annotation.
Vision Encoders’ scalability bottleneck:
- Labeled Image Data Scarcity: Creating large, high-quality, labeled image datasets like ImageNet is expensive, time-consuming, and labor-intensive.
- Supervised Tasks Might Not Scale Representations as Effectively: While image classification is important, it might not be as effective in learning general-purpose visual representations as self-supervised tasks are for language. Supervised classification can be more focused on task-specific features.
- Data Labeling Bias and Limitations: Labeled datasets can also introduce biases based on the annotators and the labeling process itself. The categories are pre-defined and might not capture the full richness of visual information.
Are Transformers Really Suitable for Vision Tasks?
And to think about it, transformers were created for sequential data, not for images.
ViTs treat images like sequences of words, but is this really effective?
Compared to CNNs, ViTs have a weaker inductive bias towards local spatial structures!
Take a closer look at the ViT architecture; you’ll see that after patching the image, each patch is then flattened and goes through a linear layer to get the embeddings. So, the local spatial structures are lost in this process.
Why are modern VLMs using ViTs?
However, modern VLMs are still using ViTs as their primary image encoder architecture. This really makes me wonder why.
I think there are two main reasons:
- Transformers are more scalable and easier to parallelize than CNNs
- It aligns well with the text encoder in the multimodal architecture
With my limited knowledge, I can’t think of any other reasons.
So, let’s move on to the next section: Research and Learn.
Research and Learn
Inductive Biases: Transformers vs. CNNs
The inductive biases of Vision Transformers and CNNs differ significantly, which impacts their learning and performance:
- CNNs:
- Have a strong inductive bias towards local spatial structures due to their convolutional layers.
- Excel in capturing local patterns and spatial hierarchies.
- Demonstrate translation invariance through weight sharing and pooling.
- Vision Transformers:
- Capture global context more effectively due to self-attention mechanisms.
- Offer more flexibility in focusing on different parts of the image based on the task.
- Lack the strong spatial inductive biases of CNNs, which can be both an advantage and a limitation.
This difference in inductive biases means that ViTs may require larger datasets to achieve optimal performance, especially when compared to CNNs in scenarios with limited data. However, the flexibility of ViTs allows them to potentially achieve higher performance ceilings, particularly in data-rich environments.
Supervised Learning in Vision Transformers
My observation about ViTs primarily using supervised learning, in contrast to the self-supervised approaches common in language models like BERT and GPT, is correct. This difference does present potential limitations:
- Data Dependency: Supervised learning in ViTs necessitates large labeled datasets, which can be costly and time-consuming to create.
- Generalization: The reliance on labeled data may limit the model’s ability to generalize to unseen tasks or domains.
However, it’s important to note that this limitation is not inherent to the transformer architecture itself, but rather to the training paradigms commonly used for vision tasks.
Emerging Self-Supervised and Unsupervised Techniques
Contrary to my concern, there has been significant progress in developing self-supervised and unsupervised learning techniques for Vision Transformers:
Contrastive Learning: This technique aligns image and text embeddings in a shared space, minimizing the distance between matched pairs and maximizing it for mismatched pairs. Models like CLIP have successfully used this approach.
Masked Image Modeling (MIM): Inspired by masked language modeling in NLP, MIM involves masking parts of an image and training the model to predict the masked regions.
These self-supervised techniques are addressing the limitations I identified before, potentially enhancing the learning effectiveness of Vision Transformers in VLMs.
Effectiveness of Vision–Language Model Learning
- Representation Quality: Recent studies show that self-supervised vision transformers (and by extension, multimodal models that incorporate them) learn representations that capture both global structure (e.g., object shape) and local details (e.g., texture) in a complementary way.
- Multimodal Alignment: Models like CLIP have demonstrated that by jointly learning visual and textual representations using contrastive loss, one can achieve impressive zero-shot classification performance. This shows that the learning is not only “effective” but also broadly generalizable across tasks.
- Data Efficiency and Scaling: While transformers require enormous datasets to reach their full potential, recent innovations in self-supervised learning have reduced this data dependency. The development of models like DINOv2 illustrates that with the right training strategy, vision models can learn effectively even when annotations are scarce.
Conclusion and Final Thoughts
New things I have learned:
- VLMs are evolving rapidly, with emerging techniques already addressing earlier shortcomings that I identified.
- Vision Transformers (ViTs) are favored for their ability to capture global context better than CNNs, making them ideal for multimodal tasks.
- Recent advances in self-supervised learning for vision tasks, this is an interesting area to explore further.
This is a great learning experience for me, and I hope it has been informative for you as well. If you have any thoughts or questions, feel free to share them in the comments below!